
ch1 libOS
本文是参加2025春夏季开源操作系统训练营时对第二阶段文档第1章做的笔记。
文档:https://learningos.cn/rCore-Camp-Guide-2025S
完整版文档:https://rcore-os.cn/rCore-Tutorial-Book-v3
引言
本章主要是讲解如何设计和实现建立在裸机上的执行环境,并让应用程序能够在这样的执行环境中运行。
编译器编译出的应用软件在缺省情况下是要链接标准库,而标准库是依赖于操作系统的,首先需要写出不需要标准库的软件并通过编译。为此,先把一般应用所需要的标准库的组件给去掉,然后再逐步添加不需要操作系统的极少的运行时支持代码,让编译器能够正常编译出不需要标准库的正常程序。
应用程序执行环境与平台支持
计算机科学中遇到的所有问题都可通过增减一层抽象来解决。
抽象的优点在于它让上层以较小的代价获得所需的功能,并同时可以提供一些保护。但抽象同时也是一种限制,会丧失一些应有的灵活性。我们通过应用程序的特征和需求来判断操作系统需要什么程度的抽象和功能。现在的操作系统,如Linux,为了通用性,而实现了大量的功能。但对于非常简单的程序而言,有很多的功能是多余的。
现代编译器工具集(以C或Rust编译器为例)的主要工作流程如下:
- 源代码(source code) –> 预处理器(preprocessor) –> 宏展开的源代码
- 宏展开的源代码 –> 编译器(compiler) –> 汇编程序
- 汇编程序 –> 汇编器(assembler)–> 目标代码(object code)
- 目标代码 –> 链接器(linker) –> 可执行文件(executables)
Rust编译器通过目标三元组 (Target Triplet) 来描述一个软件运行的目标平台。它一般包括 CPU、操作系统和运行时库等信息。
GNU libc封装了 Linux 系统调用,并提供 POSIX 接口为主的函数库。elf 表示没有标准的运行时库(表明没有任何系统调用的封装支持),但可以生成 ELF 格式的执行程序。
Rust 有一个对 Rust 语言标准库–std 裁剪过后的 Rust 语言核心库 core。core库不需要任何操作系统支持。
移除标准库依赖
本地编译与交叉编译
下面指的 平台 主要由CPU硬件和操作系统这两个要素组成。
本地编译,即在当前开发平台下编译出来的程序,也只是放到这个平台下运行。如在 Linux x86-64 平台上编写代码并编译成可在 Linux x86-64 同样平台上执行的程序。
交叉编译,是一个与本地编译相对应的概念,即在一种平台上编译出在另一种平台上运行的程序。程序编译的环境与程序运行的环境不一样。
内核第一条指令(基础篇)
(在CS61C里看到过差不多的:Lec28-31 Virtual Memory, IO#Operating Systems Basic)
Qemu 启动流程
在Qemu模拟的virt硬件平台上,物理内存的起始物理地址为0x80000000(risc-v架构常见,x86-64一般为ffff880000000000)。
计算机加电之后的启动流程可以分成若干个阶段,每个阶段均由一层软件或 固件 负责,每一层软件或固件的功能是进行它应当承担的初始化工作,并在此之后跳转到下一层软件或固件的入口地址,也就是将计算机的控制权移交给了下一层软件或固件。Qemu 模拟的启动流程则可以分为三个阶段:第一个阶段由固化在 Qemu 内的一小段汇编程序负责;第二个阶段由 bootloader 负责;第三个阶段则由内核镜像负责。
- 第一阶段将文件加载到qemu物理内存中,初始化PC寄存器,其中涉及到一些qemu固定的物理地址。
- 第二阶段跳转到bootloader的起始地址,bootloader 负责对计算机进行一些初始化工作,并跳转到下一阶段软件的入口
- 第三阶段跳转到内核,控制权被移交给内核
真实计算机的启动流程
- 第一阶段:加电后 CPU 的 PC 寄存器被设置为计算机内部只读存储器(ROM,Read-only Memory)的物理地址,随后 CPU 开始运行 ROM 内的固件,对 CPU 进行一些初始化操作,将后续阶段的 bootloader 的代码、数据从硬盘载入到物理内存,最后跳转到适当的地址将计算机控制权转移给 bootloader 。Qemu 上的固件非常简单,因为它并不需要负责将 bootloader 从硬盘加载到物理内存中,这个任务此前已经由 Qemu 自身完成了。
- 第二阶段:bootloader 同样完成一些 CPU 的初始化工作,将操作系统镜像从硬盘加载到物理内存中,最后跳转到适当地址将控制权转移给操作系统。一般情况下 bootloader 需要完成一些数据加载工作,这也就是它名字中 loader 的来源。对应于 Qemu 启动的第二阶段。在 Qemu 中,我们使用的 RustSBI 功能较弱,它并没有能力完成加载的工作,内核镜像实际上是和 bootloader 一起在 Qemu 启动之前加载到物理内存中的。
- 第三阶段:控制权被转移给操作系统内核。
为了让计算机的启动更加灵活,bootloader 目前可能非常复杂:它可能也分为多个阶段,并且能管理一些硬件资源,从复杂性上它已接近一个传统意义上的操作系统。
程序内存布局与编译流程
(CS61C中看到过差不多的:Lec11-13 Instruction Formats#compiler)
汇编器输出的每个目标文件都有一个独立的程序内存布局,它描述了目标文件内各段所在的位置。而链接器所做的事情是将所有输入的目标文件整合成一个整体的内存布局。在此期间链接器主要完成两件事情:
- 第一件事情是将来自不同目标文件的段在目标内存布局中重新排布。
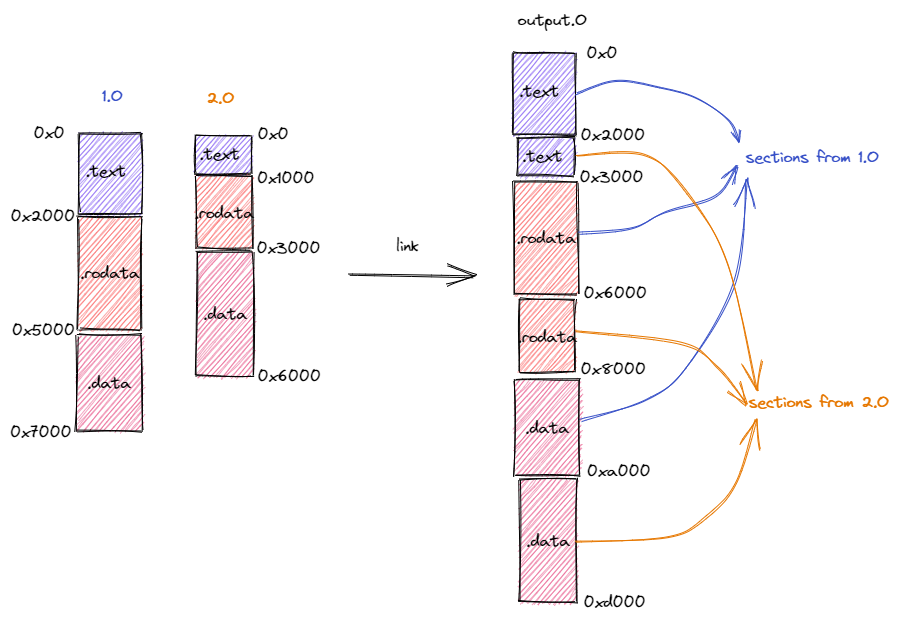
- 第二件事情是将符号替换为具体地址。
内核第一条指令(实践篇)
如果一个程序全程都使用相对地址而不依赖任何绝对地址,那么只要保持好各段之间的相对位置不发生变化,将程序整体加载到内存中的任意位置程序均可正常运行。在这种情况下,
BASE_ADDRESS可以为任意值,我们可以将程序在内存中随意平移。这种程序被称为位置无关可执行文件(PIE,Position-independent Executable)。相对的,如果程序依赖绝对地址,那么它一定有一个确定的内存布局,而且该程序必须被加载到与其内存布局一致的位置才能正常运行。
静态链接与动态链接
静态链接是指程序在编译时就将所有用到的函数库的目标文件链接到可执行文件中,这样会导致可执行文件容量较大,占用硬盘空间;而动态链接是指程序在编译时仅在可执行文件中记录用到哪些函数库和在这些函数库中用到了哪些符号,在操作系统执行该程序准备将可执行文件加载到内存时,操作系统会检查这些被记录的信息,将用到的函数库的代码和数据和程序一并加载到内存,并进行一些重定位工作。
编译得到的可执行文件除了实际会被用到的代码和数据段之外还有一些多余的元数据,需要使用类似如下命令将其丢弃。
1 | rust-objcopy --strip-all target/riscv64gc-unknown-none-elf/release/os -O binary target/riscv64gc-unknown-none-elf/release/os.bin |
在 os 目录下通过以下命令启动 Qemu 并加载 RustSBI 和内核镜像:
1 | qemu-system-riscv64 \ |
- 其中的
rustsbi-qemu.bin是一个用 Rust 编写的 RISC-V Supervisor Binary Interface (SBI) 实现,相当于操作系统(或运行时环境)与硬件和固件(如引导程序或内核)进行交互的中间层,介于底层硬件和内核之间,内核的底层执行环境。
为内核支持函数调用
(函数调用与栈的部分在CS61C里也看到过差不多的:Lec7-10 RISC-V#Function Calls)
栈通常是通过指定内存中的一块特定区域来实现的,由操作系统来管理。
C 语言中的指针相当于 Rust 中的裸指针,Rust 编译器没法确认程序员对它的使用是否安全,因此将其划到 unsafe Rust 的领域。
基于 SBI 服务完成输出和关机
我们编写的 OS 内核位于 Supervisor 特权级,而 RustSBI 位于 Machine 特权级,也是最高的特权级。和U模式下的系统调用中ecall的使用类似,S模式下也是通过ecall来进入M模式。调用 RustSBI 提供的服务通常像调用函数一样,但底层通过 ecall 指令和特权模式的切换实现。
练习
(不是很明白到底要干什么,现在看到的ch1分支似乎是已经实现好的,参考ch1分支自己试了一下)
对LOG参数的支持,ch1分支中实现好的Makefile里没有对LOG参数的处理,我感到疑惑,找了一下发现在这里:
1 | // os/src/logging.rs:39 |
是通过获取环境变量的方式来生成运行时分支执行的方式,因为Makefile中没有用到LOG参数的命令所以没有写出来。