
CPU虚拟化
OSTEP(Operation Systems Three Easy Pieces)的CPU虚拟化部分,3到9章。
进程
计算机通过时分共享CPU提供了虚拟化CPU的假象。操作系统为正在运行的程序提供的抽象就是进程,进程是正在运行中的程序,一般情况下操作系统会使用一些数据结构追踪进程的状态,包括上下文,地址空间,pid,进程栈,所在目录等。
构建时分共享CPU时,有两个挑战,首先是性能开销,然后是保留操作系统对CPU的控制权。如果没有控制权,一个进程可以简单地无限制运行并接管机器,或访问没有权限的信息。为了提高性能,采用受限直接执行,直接执行指程序直接在硬件 CPU 上运行,受限指CPU引入的运行权限,用户程序运行在用户模式,内核运行在内核模式。如果用户希望进行特权操作,只能通过系统调用完成,具体是通过trap指令(例如riscv中的ecall)陷入到内核模式执行,参数放在栈上或约定好的寄存器内。执行trap时,每个程序的一些信息(寄存器,标志位等,可能称为trap上下文)被被保存在每个程序的内核栈中。内核在启动的时候配置好trap table来设置trap时跳转的地址。
权限
切换进程时,由于进程正在占用CPU,所以操作系统没有在CPU上运行,这种情况下操作系统似乎没有办法采取行动。一些操作系统中采用协作式:假定应用程序都是友好的,会运行一段时间主动释放CPU(通过系统调用实现,例如yield),这种协作式操作系统在早期比较常见。但是对用户程序编写者不是很友好,而且如果用户程序不释放CPU,操作系统没有什么办法收回控制权。在非协作式的操作系统中,操作系统通过预先配置中断处理程序和时钟中断,每隔一段时间中断触发,控制权就会回到操作系统。
进程调度
在进行进程切换时,操作系统需要进行上下文切换,为当前正在执行的进程保存一些寄存器的值(保存到它的内核栈) ,并为即将执行的进程恢复一些寄存器的值(从它的内核栈) 。切换上下文时,进程的内核栈指针也会更换,通过切换栈,内核在进入切换代码调用时,是一个进程(被中断的进程)的上下文,在返回时,是操一进程(即将执行的进程)的上下文。当操作系统最终执行从陷阱返回指令时,即将执行的进程变成了当前运行的进程。
在进程调度中,首先提出一些工作负载的假设,然后使用周转时间作为性能指标,别的指标还有公平性,公平性和性能通常是相矛盾的。一些最基本的调度算法有fifo,最短任务优先,最短完成时间优先等。在批处理系统中使用周转时间就很好了,但是在分时系统中,用户需要与操作系统进行交互,这需要保证交互性,引入响应时间作为新的性能指标,为了解决交互性,提出了轮转算法,让每个任务运行一个时间片再进入到下一轮调度,时间片的长度需要合适,太短会增加上下文切换的开销,太长会增加响应时间。在加入IO操作的情况下,由于进行IO操作时进程不占用CPU且IO操作一般时间较长,在IO中断时可以切换其它的进程到CPU上运行。 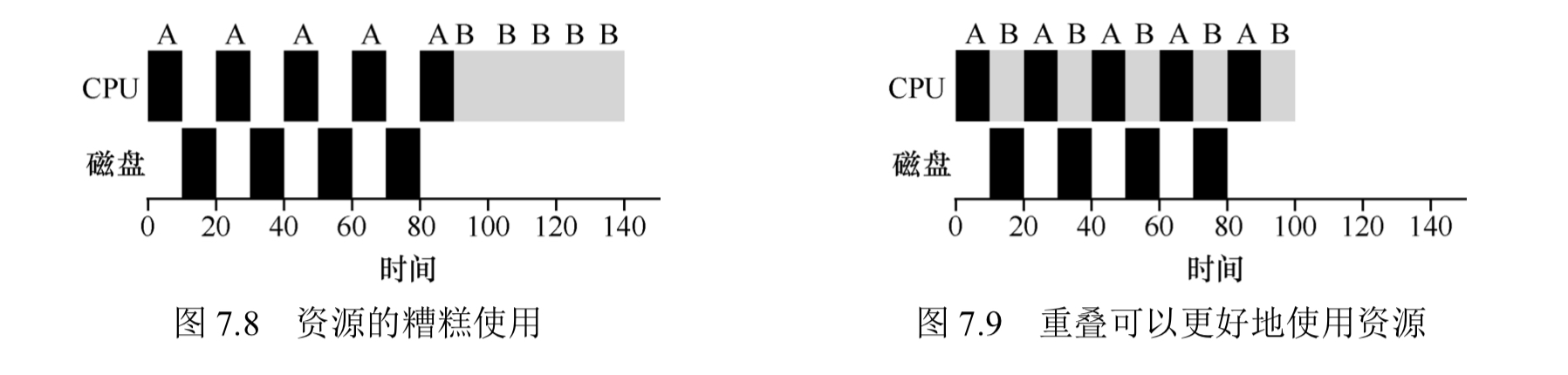
但是,周转时间需要得知进程的运行时间,这是无法预知的,这可以通过多级反馈队列解决。
多级反馈队列(MLFQ)首先要优化周转时间,因为操作系统不知道进程的运行时间,其次,操作系统还想要降低响应时间。MLFQ中有许多并列的队列,拥有不同的优先级,在同一时刻,一个工作只能处于一个队列中,对于一个队列中的许多工作使用轮转算法,MLFQ的关键在于如何设置优先级,它根据观察到的行为调整它的优先级。例如,如果一个工作不断放弃CPU 去等待键盘输入,这是交互型进程的可能行为,MLFQ 因此会让它保持高优先级。相反,如果一个工作长时间地占用 CPU,MLFQ 会降低其优先级。
规则 1:如果 A 的优先级 > B 的优先级,运行 A(不运行 B)。
规则 2:如果 A 的优先级 = B 的优先级,轮转运行A 和 B。
规则 3:工作进入系统时,放在最高优先级(最上层队列)。
规则 4a:工作用完整个时间片后,降低其优先级(移入下一个队列)。
规则 4b:如果工作在其时间片以内主动释放CPU,则优先级不变。
如果不知道工作是短工作还是长工作,那么就在开始的时候假设其是短工作,并赋予最高优先级。如果确实是短工作,则很快会执行完毕,否则将被慢慢移入低优先级队列,而这时该工作也被认为是长工作了。通过这种方式,MLFQ 近似于 SJF。
在有IO的情况下,根据4b,如果进程在时间片用完之前主动放弃 CPU,则保持它的优先级不变,这样可以让交互型工作快速运行。
目前的MLFQ看起来非常好,但是,如果高优先级有太多交互型任务,它们的优先级不会降低,轮流占用CPU,会让低优先级的任务无法运行。其次,聪明的用户会重写程序,愚弄调度程序。
为了避免饥饿,一个简单的思路是周期性地提高所有任务的优先级:
规则 5:经过一段时间 S,就将系统中所有工作重新加入最高优先级队列。这个S也需要设置成合适的值。
为了避免愚弄调度程序,这里的罪魁祸首是导致工作在时间片以内释放 CPU,就保留它的优先级。将4a和4b改为:
规则 4:一旦工作用完了其在某一层中的时间配额(无论中间主动放弃了多少一CPU),就降低其优先级(移入低一级队列)。
MLFQ的原理已经理清了,对于细节问题,例如需要多少队列,时间片设置成多大,需要在实践中调整,通常不同优先级的队列有不同大小的时间片,优先级越低的队列时间片越长,因为其中更可能是CPU密集型工作,有一些优化的MLFQ中还会使用数学公式计算。MLFQ对于短时间运行的交互型工作,获得类似于 SJF/STCF 的很好的全局性能,同时对长时间运行的CPU 密集型负载也可以公平地运行,所以它在很多操作系统中都很受欢迎。
除了MLFQ,还有许多其他类型的调度程序,例如比例份额调度程序,它的想法是确保每个工作获得一定比例的 CPU 时间,而不是优化周转时间和响应时间。比例份额调度程序有一个非常优秀的现代例子,名为彩票调度,基本思想很简单:每隔一段时间,都会举行一次彩票抽奖,以确定接下来应该运行哪个进程。越是应该频繁运行的进程,越是应该拥有更多地赢得彩票的机会。
彩票数代表了进程占有资源(例如CPU)的份额,每次选一个彩票的持有者进行调度,这利用了随机性,所以在概率上满足期望的比例,但不一定完全相同,工作运行的时间越长,实际比例与期望的比例越接近。与之配套的还有彩票转移,彩票通胀机制等,它的真实实现也很简单,只需要一些相应的数据结构即可。还有一个问题是如何分配彩票给不同的进程,这个问题目前没有最佳答案(啊?)
彩票调度使用了随机性,如果使用确定性的话,例如步长调度程序,虽然可以更加精确地调度,但是这需要记录每个进程的全局状态,而彩票调度不需要。这两种调度程序目前都不太流行,因为对IO的情况处理的不太好,而且彩票调度中票数分配没有最佳答案,这两种调度程序只在特定的领域受欢迎,例如在虚拟机分配程序中。